
CS231n 7강 요약
Neural Network를 Training 시킬 때, 고려해야 하는 것들을 추가적으로 알아보자!
0. Today’s Goal
- Optimization의 여러가지 기법들
- Regularization
- Transfer Learning
1. 강의 및 강의 자료
강의를 들어볼 수 있는 링크와 강의 자료를 pdf형식으로 준비했다.
한글 자막이 필요하신 분은 다음의 링크를 확인해주세요. :)
- 한글 자막을 첨부하고 싶으면 여기를 눌러주세요.
2. Optimization의 여러가지 기법들
다양한 Optimization Algorithm 소개
지금까지 배운 최적화 기법은 SGD Algorithm이 있다.
간단하게 SGD Algorithm에 대해 설명해보면,
- Mini batch 안에 있는 data의 loss를 계산
- Gradient의 반대 방향을 이용하여 update를 한다.
- 1번과 2번 과정을 계속해서 반복한다.
하지만 SGD Algorithm에는 문제점이 존재하는데,
- Loss의 방향이 한 방향으로만 빠르게 바뀌고 반대 방향으로는 느리게 바뀐다면 어떻게 될 것인가?

이렇게 불균형한 방향이 존재한다면 SGD는 잘 동작하지 않는다.
- Local minima나 saddle point의 빠지면 어떻게 될 것인가?

최솟값이 더 있는데 local minima에 빠져서 나오지 못하거나,
기울기가 완만한 구간에서 update가 잘 이루어지지 않을 수 있다.
- Minibatches에서 gradient의 값이 노이즈 값에 의해 많이 변할 수 있다.

그림처럼 꼬불꼬불한 형태로 gradient 값이 update 될 수 있다.
위와 같은 문제점들을 해결하기 위해서 Momentum이라는 개념을 도입한다.
Momentum이란 자기가 가고자 하는 방향의 속도를 유지하면서 gradient update를 진행하는 것을 말한다.

momentum을 추가하는데 기존에 있는 momentum과는 다르게 순서를 바꾸어 update를 시켜주는 방법도 있는데 Nesterov Momentum이라고 한다.


식의 의미를 잘 이해하진 못했지만,
강의에서는 현재 / 이전의 velocity 간의 에러 보정이 추가되었다고 설명했다.
기존의 SGD, SGD+Momentum, Nesterov의 결과값을 한 번 비교해보면,

좀 더 Robust하게 algorithm이 작동하는 것을 볼 수 있다.
Velocity term 대신에 grad squared term을 이용하여
gradient를 update하는 방법도 제안되었는데,
이 방법은 AdaGrad라고 부른다.
AdaGrad는 학습률을 효과적으로 정하기 위해 제안된 방법이다.
grad squared term를 추가하게 되면, 각각의 매개변수에 맞춤형으로 값을 정해줄 수 있다.

이러한 방식으로 update를 계속 진행하게 되면,
small dimension에서는 가속도가 늘어나고,
large dimension에서는 가속도가 줄어드는 것을 볼 수 있다.
그리고 시간이 지나면 지날수록 step size는 점점 더 줄어든다.
이 방법에서 또 하나가 추가가 되어 decay_rate라는 변수를 통해서
step의 속도 가 / 감속을 할 수 있는 방법이 제안되었는데,
이 방법을 RMSProp이라고 한다.
RMSProp는 AdaGrad의 단점을 보완한 방법이다.
과거의 모든 기울기를 균일하게 반영해주는 AdaGrad와 달리,
RMSProp은 새로운 기울기 정보에 대하여 더 크게 반영하여 update를 진행한다.

정말 수많은 알고리즘들이 제안되었는데,
이제 대중적으로 널리 쓰이고 있는 Adam에 대해서 알아보자.
Adam은 쉽게 생각하면 momentum + adaGrad 라고 생각하면 된다.

초기화를 잘 해주어야 하기 때문에, bias correction을 추가하여
초기화가 잘 되도록 설계해 주었다.
앞선 알고리즘과 한번 비교를 해보면,

음.. Adam이 제일 대중적으로 쓰인다고 했는데
여기 보여준 예제에서는 좀 멀~리 돌아서 update가 된 것 같긴하다.
최적화 기법은 상황에 따라 최적의 최적화 기법이 모두 다르다!
지금까지 보여준 최적화 알고리즘은
모두 Learning rate를 hyperparameter로 가지고 있다.
Learning rate decay도 있지만
처음에는 없다고 생각하고 딥러닝 모델을 설계한 다음,
나중에 고려해주도록 하자.
First-Order & Second-Order Optimization
일차 함수로 근사화를 시켜 최적화를 시킬 때는 멀리 갈 수 없다는 단점이 있다.

이차 함수로 근사화를 시킬때는 주로 테일러 급수를 이용해서 근사화를 시킨다.
이러한 방법으로 update를 시키면 기본적으로 learning rate를 설정해 주지 않아도 된다는 장점이 있다. (No Hyperparameters!)
하지만 복잡도가 너무 크다는 단점이 있다.

이차 함수로 근사화 시키는 일은 Quasi-Newton 방법으로
non-linear한 최적화 방법 중에 하나이다.
Newton methods보다 계산량이 적어 많이 쓰이고 있는 방법이다.
그 중 가장 많이 쓰는 알고리즘은 BGFS와 L-BGFS이다.
이러한 알고리즘들은 full-batch일 때는 좋은 성능을 보이기 때문에,
Stochastic(확률론적) setting이 적을 경우 사용해 볼 수 있다.
지금까지 배운 방법들은 모두
Training 과정에서 error를 줄이기 위해 사용하는 방법들이다.
그렇다면 한 번도 보지 못한 데이터에서 성능을 올리기 위해서는 어떻게 해야할까?
3. Regularization
Regularization 기법을 설명하기 전에, Model Ensembles에 대해서 한 번 정리하자.
Model Ensembles은 간단히 말하면 다양한 모델로 train을 시키고,
test를 할 때 그 것들을 짬뽕(?)해서 쓰는 것을 말한다.

Test를 할 때, parameter vector들을 Moving average값을 사용하여
test를 하는 방법도 있다. (Polyak averaging)
지금까지의 방법들은 모두 Test를 하는데 좋은 성능을 내기 위해 모델을 좀 더 robust하게 만들기 위해서 사용하는 기법들이다.
그렇다면 single-model의 성능을 좋게 하기위해선 어떤 방법을 쓸까?
답은 Regularization이다.
Regularization은 간단히 loss function을 구현할 때,
regularization에 대한 function을 추가해주기도 한다.

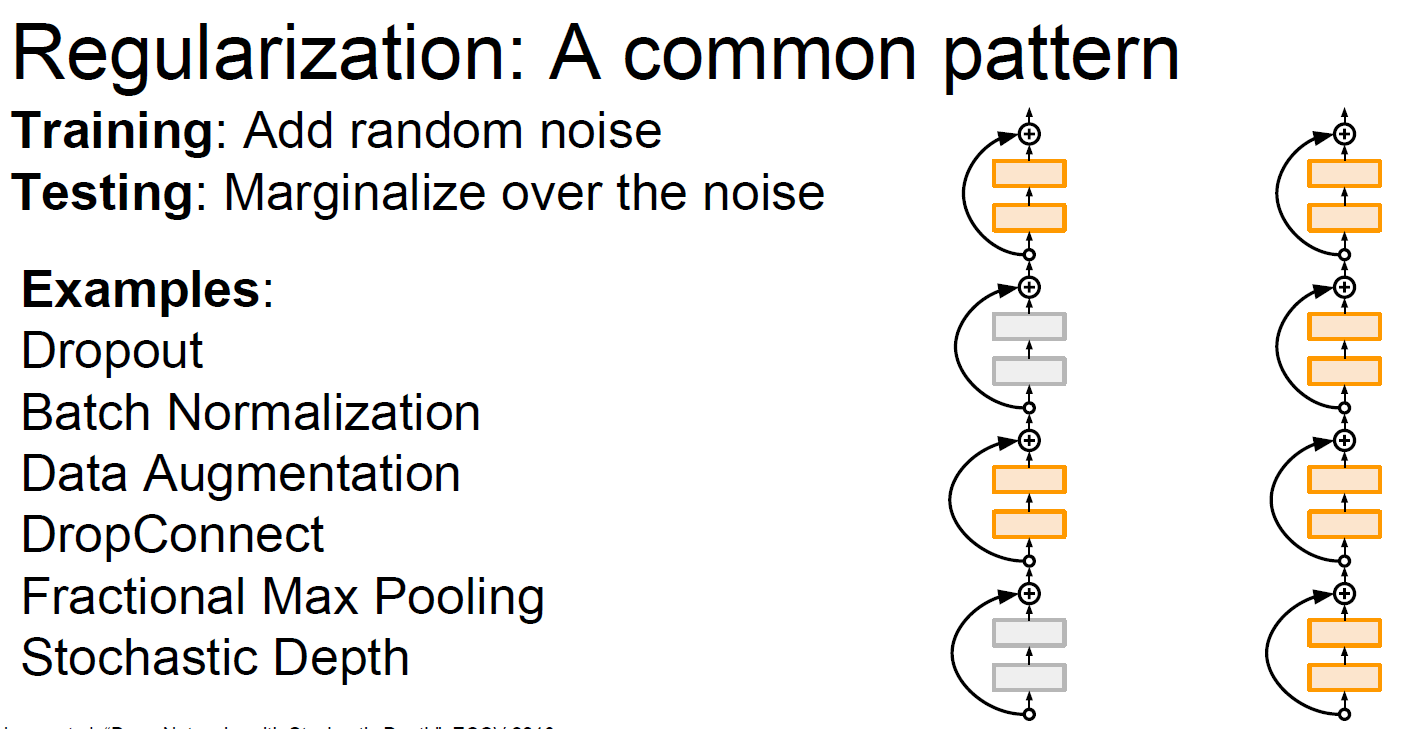
또 다른 방법으로는 dropout이라는 기법도 있다.
Dropout이 효과가 있는 이유는 다양한 feature를 이용하여 예측을 하기 때문에
어떤 특정 feature에만 의존하는 경우를 방지한다.
또한 단일 모델로 앙상블 효과가 날 수 있도록 한다.

Test-time에서 임의성에 대해 평균을 내고 싶을 때..

Dropout을 하게 되면 test time도 줄어들게 할 수 있다.
또 다른 regularization 방법으로는 Data Augmentation이 있다.
Training을 시킬 때, 이미지의 patch를 random하게 잡아서 훈련을 시키거나,

이미지를 뒤집어서 train dataset에 추가해 훈련을 해주거나,

밝기값을 다르게 해서 train dataset에 추가하고 훈련을 해주는 경우도 있다.

이 외에도 다양한 regularization 방법들이 존재한다.
4. Transfer Learning
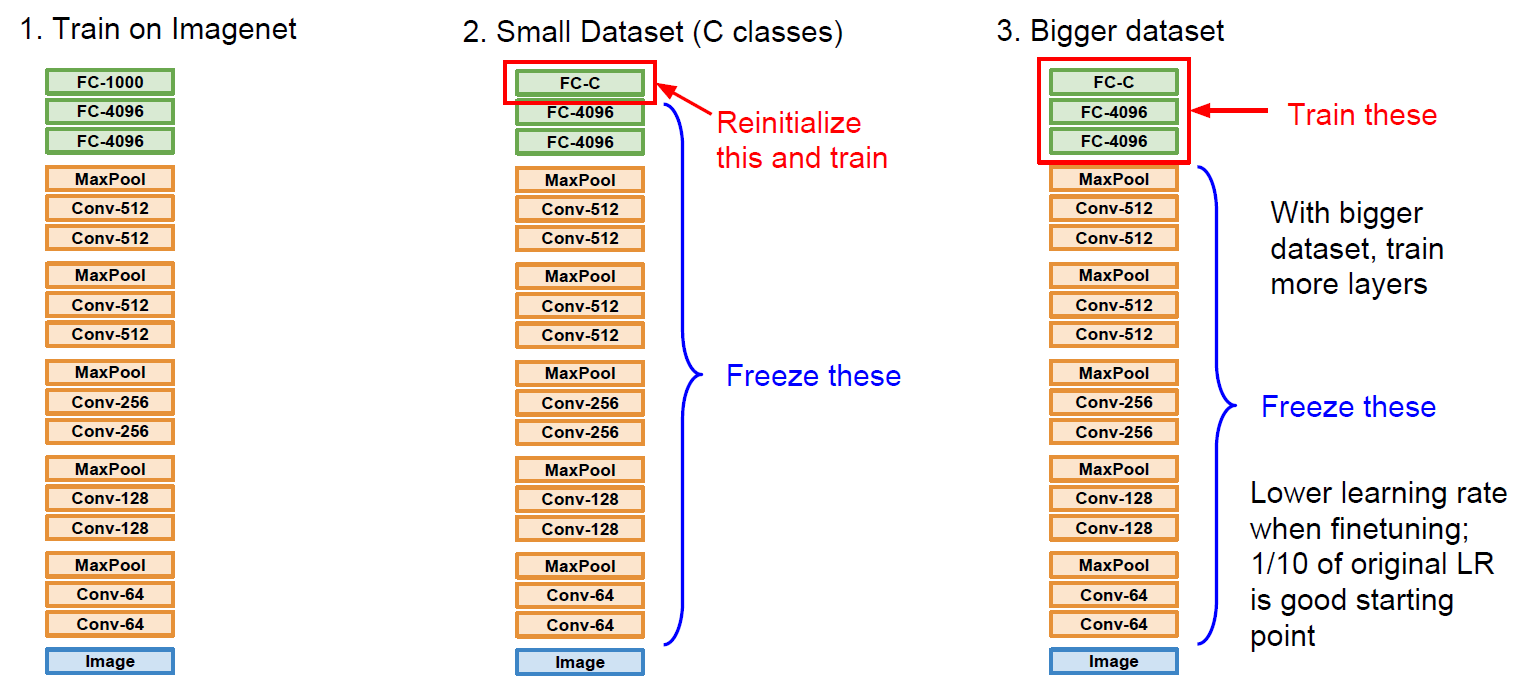
전이학습은 간단히 말하면 이미 pretrained된 모델을 이용하여 우리가 이용하는 목적에 맞게 fine tuning하는 방법을 말한다.
Small Dataset으로 다시 training 시키는 경우
보통의 learning rate보다 낮춰서 다시 training을 시킨다.
DataSet이 조금 클 경우, 좀 더 많은 layer들을 train 시킨다.
한 번 더 표로 정리해보면, 아래와 같이 나타낼 수 있다.
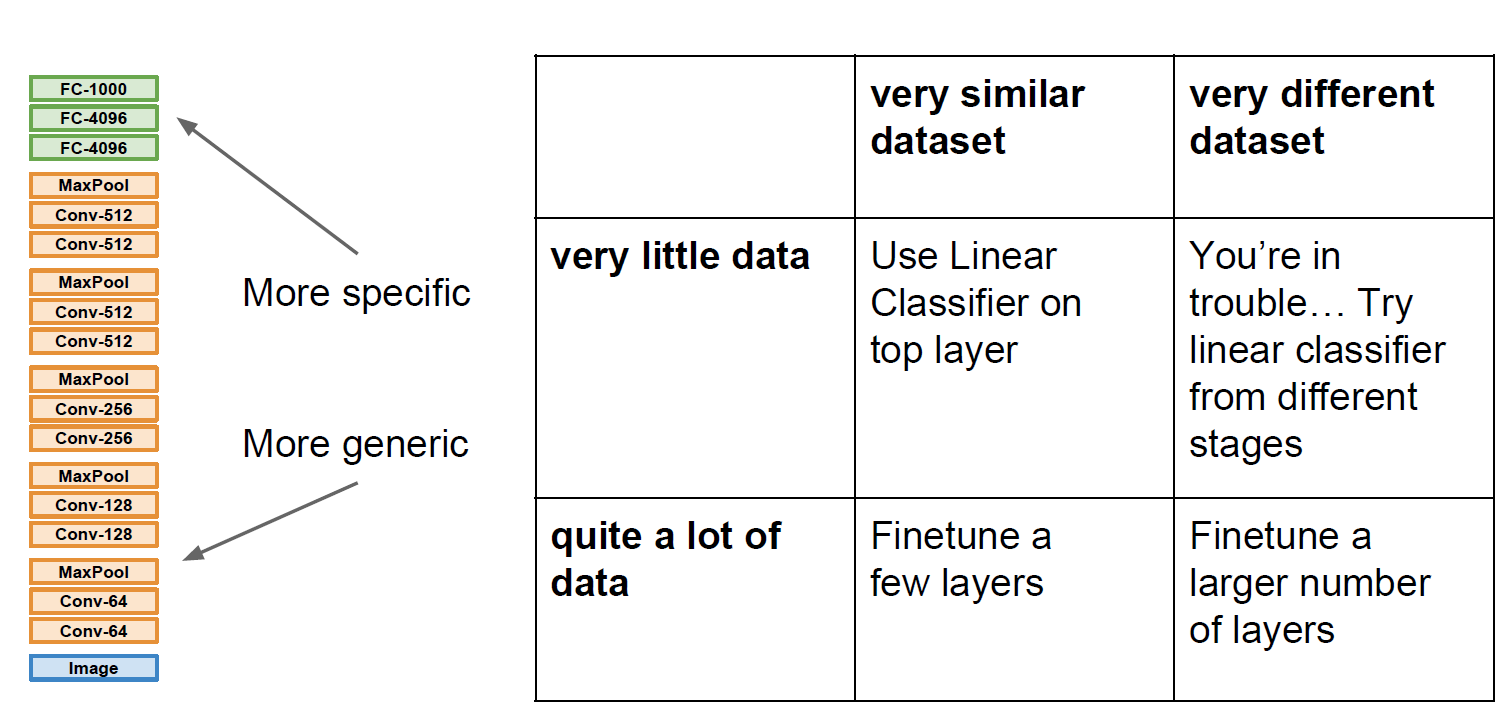
전이학습은 많이 사용하는 방법이니 꼭 알아두자!
다음 시간에는 Deep Learning Software에 대해서 배운다.
어떤 프레임워크가 있는지 한 번 알아보자.
댓글남기기